背景
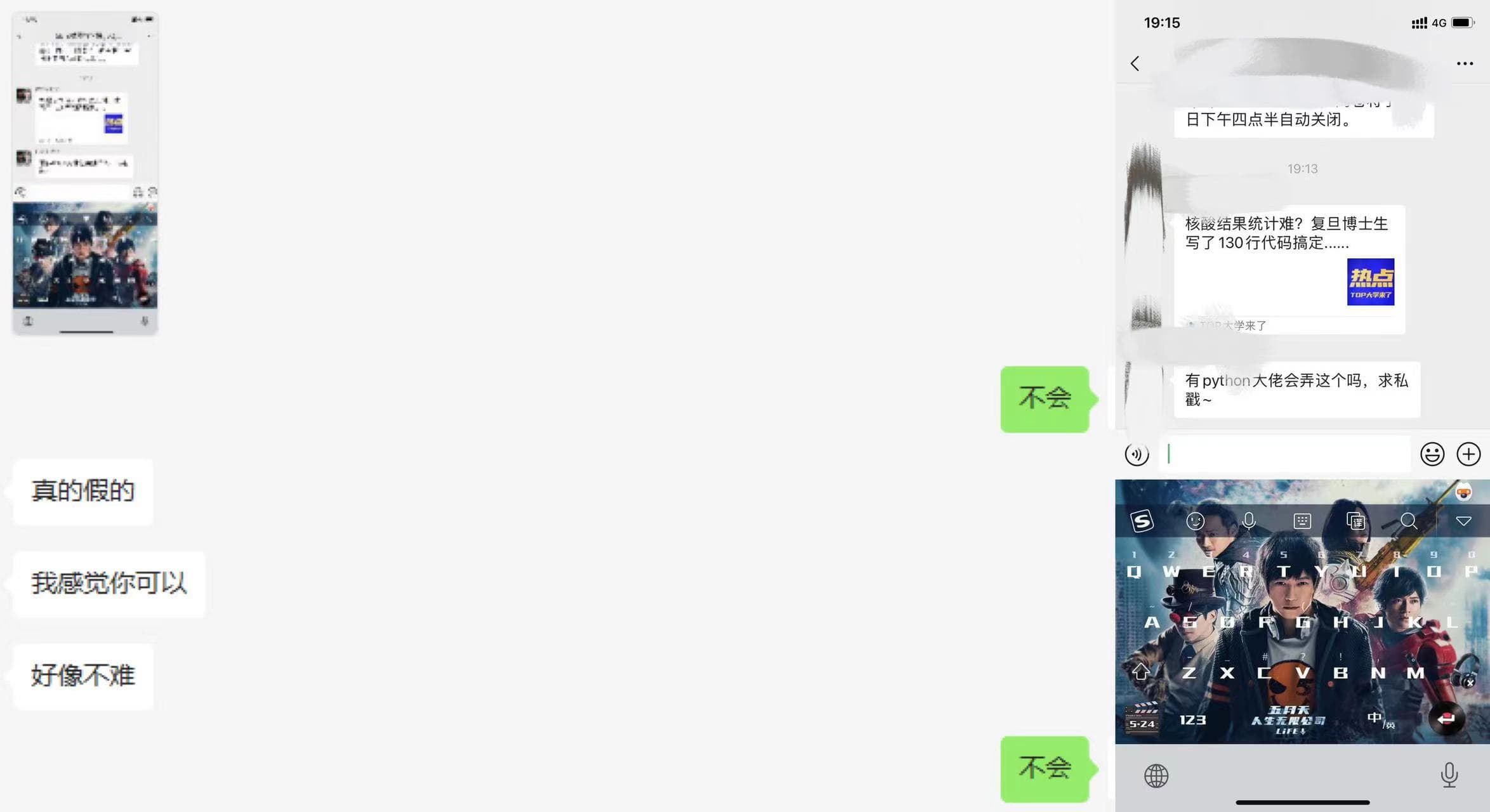
上海市疫情比较严重,可能有学校要求每天统计核酸检测结果的截图,有复旦的博士大佬搞了个自动识别核酸检测截图的小程序,并且在那边推广起来,可能我们学校有人觉得这种方法很便捷,也想整一个。
然后就有了这样的对话:

让我想想该说点什么好。

 Yaodo·2022-04-10·274 次阅读
Yaodo·2022-04-10·274 次阅读
上海市疫情比较严重,可能有学校要求每天统计核酸检测结果的截图,有复旦的博士大佬搞了个自动识别核酸检测截图的小程序,并且在那边推广起来,可能我们学校有人觉得这种方法很便捷,也想整一个。
然后就有了这样的对话:
不是我谦虚,我是真的不会。就算我能搞出来,也很麻烦。江苏的核酸检测结果都有水印,OCR的结果很可能被污染,而且我们的结果也不是每天统计,而是一周一统计,让班长们去手动收集好了。
虽然我不想搞这些,但我对文字识别还算有点兴趣。我们单位在构建新财务系统的时候,也想过自行研发一个网报系统,IT哥哥们调用的是百度的发票识别API,我看了一下价格,真的很亲民,所以这次我打算也使用百度智能云的通用OCR的API。
为什么不自己编个OCR的小程序呢,一是我不会,二是我懒,三是我不想让我的电脑承受太大负担。百度API一块钱可以识别1万次,而且每个月还可以免费领几千次,它不香吗。
网址:https://cloud.baidu.com/campaign/OCR202203/index.html

可以使用百度账号登录,使用百度登录的好处是,你可以把百度的实名认证直接迁移过来,就不需要再等几天人工审核了。
你可以选择免费试用,或者1块钱买1万次,我觉得没什么区别,都是够用的。
领取免费额度的时候要勾选接口类型,要不然是一片空白。由于我已经领取过文字识别了,所以我这就不再演示。
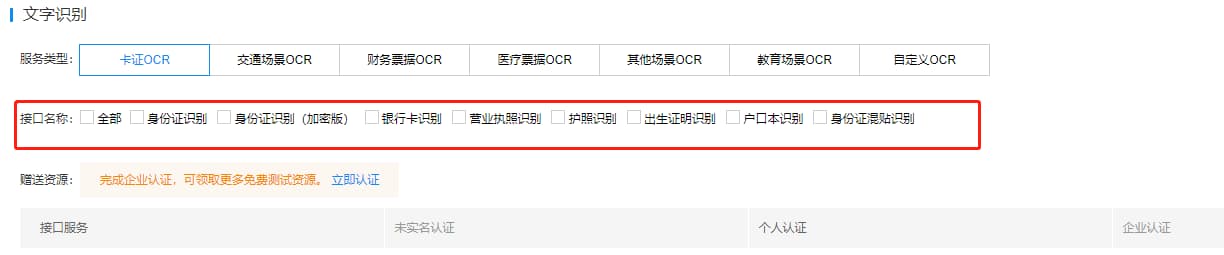
在“控制台-文字识别-概览”中点击“创建应用”
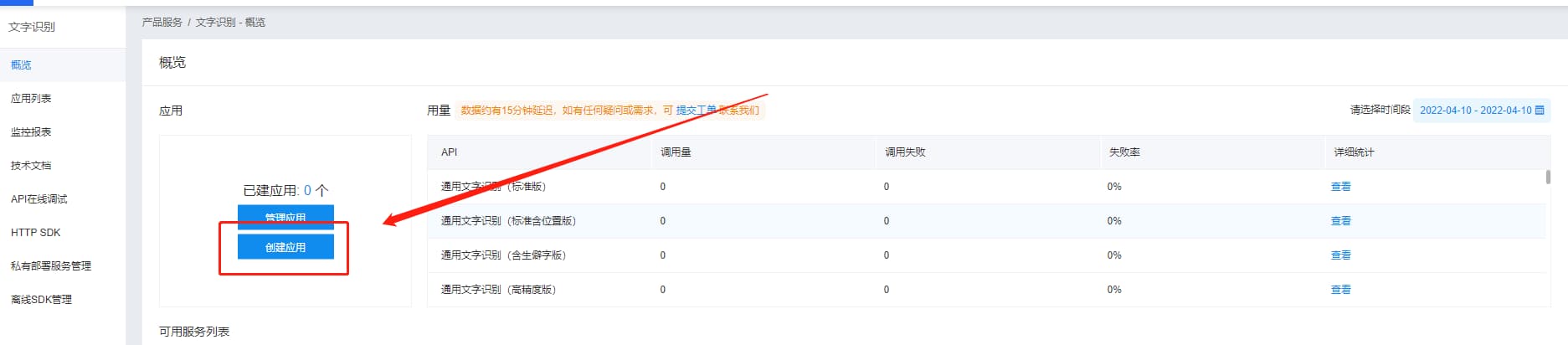
应用归属选择个人,应用名称和概述就随便填一点吧
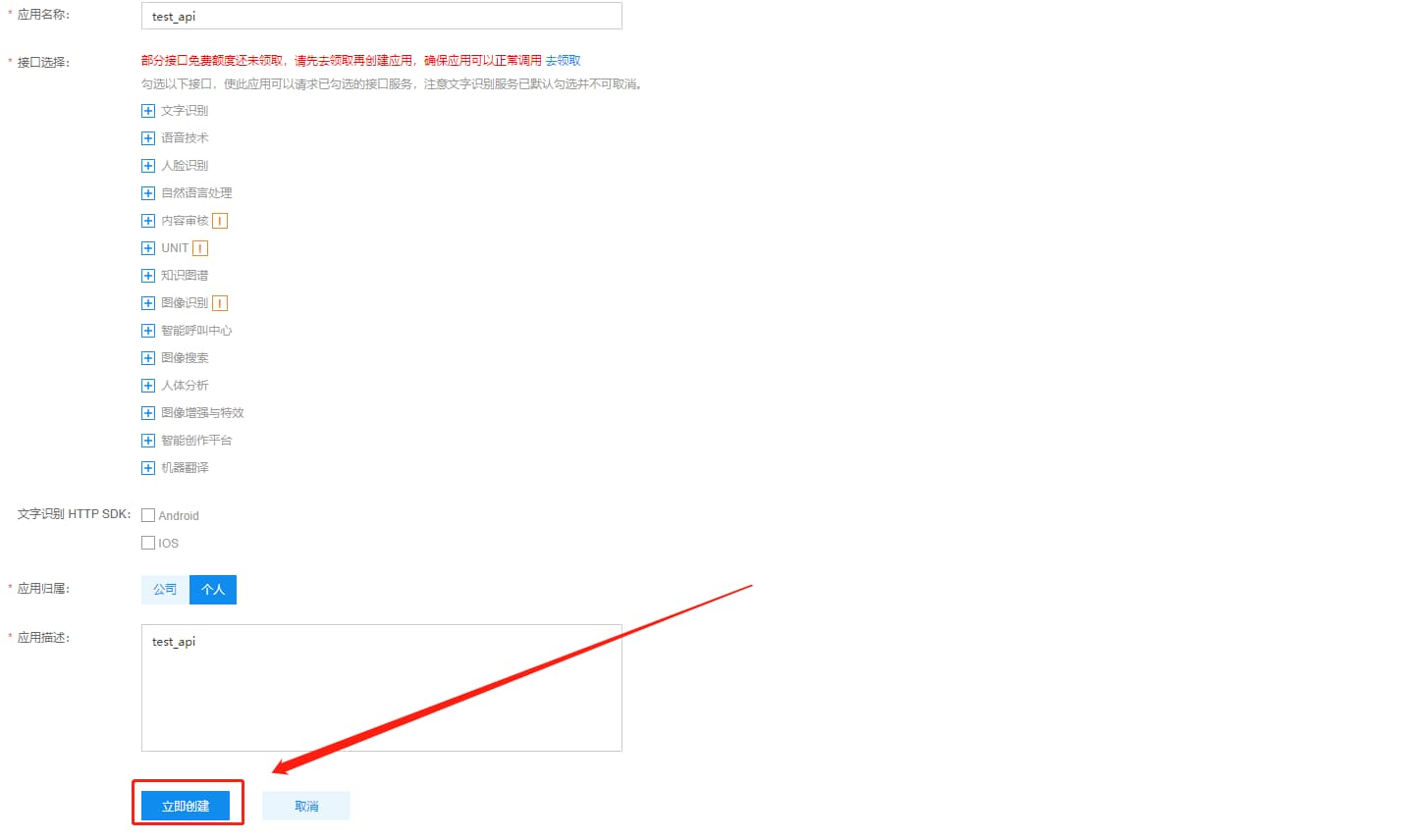
创建完成之后,进入应用列表,可以看到API Key和Secret Key,记下来。

百度提供了一个视频教程,可以参考:使用APIExplorer调用API接口
如果你也使用Python的话,不妨直接使用我的代码,必须要修改的地方有3个
其他的地方,看着改就行。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import base64
import re
from urllib.parse import quote
import copy
from baidubce import bce_base_client
from baidubce.auth import bce_credentials
from baidubce.auth import bce_v1_signer
from baidubce.http import bce_http_client
from baidubce.http import handler
from baidubce.http import http_methods
from baidubce import bce_client_configuration
# 获取AccessToken Python示例代码
class ApiCenterClient(bce_base_client.BceBaseClient):
def __init__(self, config=None):
self.access_token = ''
self.service_id = 'apiexplorer'
self.region_supported = True
self.config = copy.deepcopy(bce_client_configuration.DEFAULT_CONFIG)
if config is not None:
self.config.merge_non_none_values(config)
def _merge_config(self, config=None):
if config is None:
return self.config
else:
new_config = copy.copy(self.config)
new_config.merge_non_none_values(config)
return new_config
def _send_request(self, http_method, path,
body=None, headers=None, params=None,
config=None, body_parser=None):
config = self._merge_config(config)
if body_parser is None:
body_parser = handler.parse_json
return bce_http_client.send_request(
config, bce_v1_signer.sign, [handler.parse_error, body_parser],
http_method, path, body, headers, params)
def get_access_token(self):
path = b'/oauth/2.0/token'
headers = {}
headers[b'Content-Type'] = 'application/json;charset=UTF-8'
params = {}
params['client_id'] = '3C6o2ww0KpNWUAI1VBtVQHGi' # 请更改为你自己的API Key
params['client_secret'] = 'gGsM9Q6liKxlKNuWbjrmctMcG0xVq8MT' # 请更改为你自己的Secret Key
params['grant_type'] = 'client_credentials'
body = ''
return self._send_request(http_methods.POST, path, body, headers, params)
# 将图片以base64编码,并进行urlencode
def get_b64_body(self, path):
with open(path, 'rb') as file:
img = file.read()
b64 = base64.b64encode(img)
b64_str = 'data:image/jpg;base64,{}'.format(str(b64,'utf-8'))
body = 'image=/{}'.format(quote(b64_str))
return body
# 调用通用ocr的api进行识别
def ocr(self, access_token, path1):
path = b'/rest/2.0/ocr/v1/general_basic'
headers = {}
headers[b'Content-Type'] = 'application/x-www-form-urlencoded;charset=UTF-8'
params = {}
body = self.get_b64_body(path1)
params['access_token'] = access_token
return self._send_request(http_methods.POST, path, body, headers, params)
if __name__ == '__main__':
endpoint = 'https://aip.baidubce.com'
ak = ''
sk = ''
config = bce_client_configuration.BceClientConfiguration(credentials=bce_credentials.BceCredentials(ak, sk),
endpoint=endpoint)
client = ApiCenterClient(config)
access_token = client.get_access_token().__dict__['access_token']
path = r'C:\Users\rvw\Desktop\健康码\test.jpg' # 要识别的图片的路径
r = client.ocr(access_token, path)
l = r.__dict__['words_result']
print(l)
for i in l:
print(i.__dict__['words'])
效果如下:
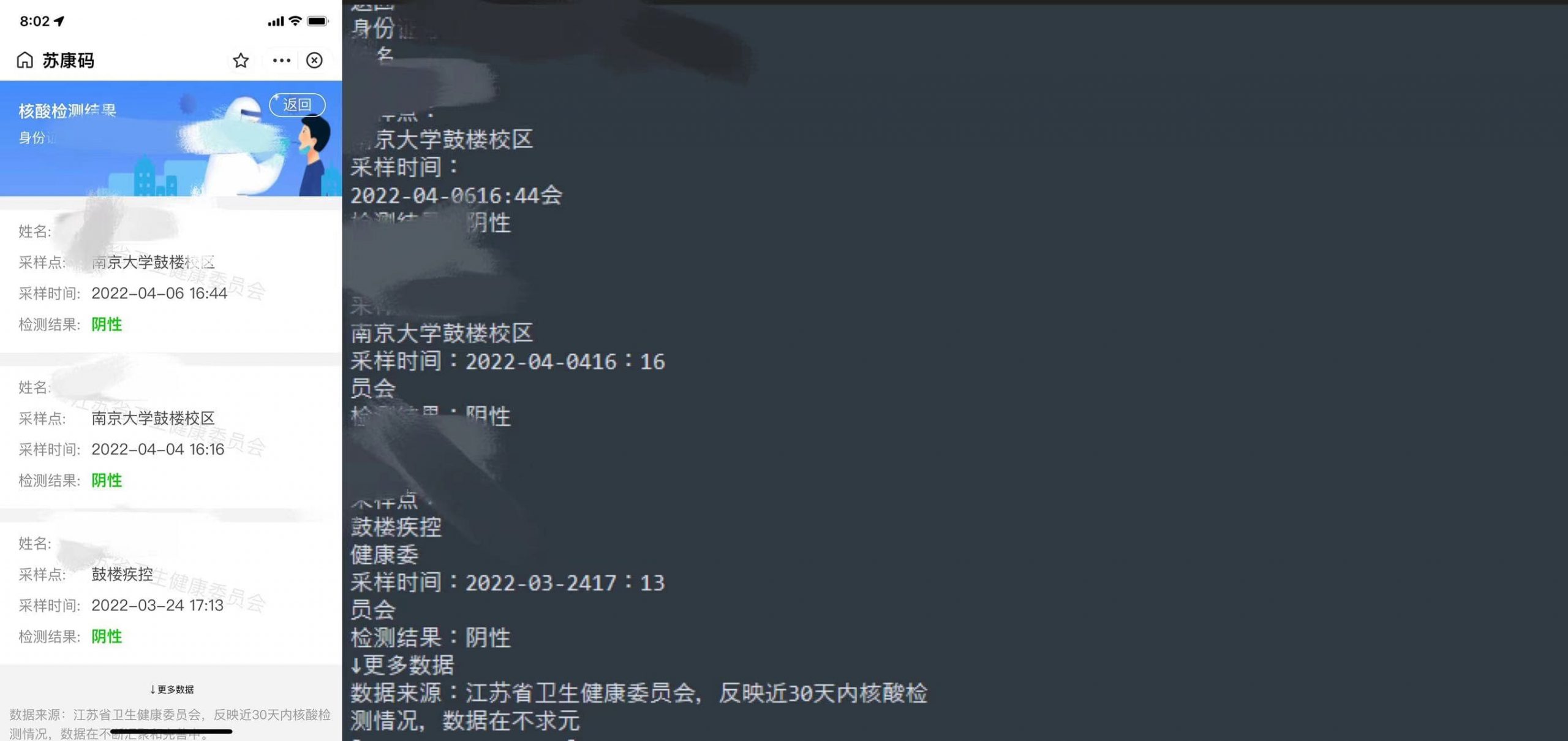
可以看到,由于加入了水印(“江苏省卫生健康委员会”)结果还是很脏的。
返回的结果是一个Expando格式的列表,如果要继续处理的话,可以通过item.__dict__转化为字典。
话说,用这个识别真的准确吗……我真的没想到什么好办法,我唯一觉得识别的还不错的是采样时间,也许可以通过匹配“-”和“:”这种妖孽做法来提取时间吧:
将93行以后的代码修改为:
path = r'C:\Users\rvw\Desktop\健康码\test.jpg'
r = client.ocr(access_token, path)
l = r.__dict__['words_result']
l = [i.__dict__['words'] for i in l]
name = l[[i for i,x in enumerate(l) if (x.find('姓名')!=-1)][0]+1]
indexs_time = [i for i,x in enumerate(l) if (x.find('-')!=-1) and ((x.find(':')!=-1) or (x.find(':')!=-1))]
tlist = []
for index in indexs_time:
numbers = ''.join(re.findall('[0-9]',l[index]))
t = '{}-{}-{} {}:{}'.format(numbers[:4],numbers[4:6],numbers[6:8],numbers[8:10],numbers[10:])
tlist.append(t)
print('姓名:{}\n最近采样时间:'.format(name))
for t in tlist:
print(t)
效果:

勉强能看吧
Comments | NOTHING